
Blog
Every deal should make the next one easier to read
A connected record of resolved deals is not storage. It is the population the engine learns from, and it compounds.
Most deal knowledge dies the moment the deal closes.
A deal throws off a lot. Transcripts, threads, a deck, CRM notes, the thread where someone finally cracked the pricing objection. Then it closes and all of it scatters back into the tools it came from. The next rep on a similar deal starts cold.
The waste is not storage. Everything is saved somewhere. The waste is that none of it is connected, so none of it can be reused. A transcript in the notetaker, notes in the CRM, the winning one-pager in a drive nobody opens. Three tools, no shared memory.
Connecting it is the boring partLink to heading
Putting all of that in one place is the obvious move, and it is not the interesting one. A unified workspace is a filing improvement. The interesting part is what a connected memory makes possible that scattered notes cannot, and to see it you have to look at the other two layers and ask what they run on. The insight layer ranks change by how much it has shifted the odds across the whole population of past deals. The action layer fires only when a precursor has enough history behind it to trust. Both of those depend on one thing: a large, connected record of deals that already resolved, with their outcomes attached. That record is the memory layer. It is not a convenience feature sitting next to the engine. It is the engine's training data.
The memory is the modelLink to heading
This is the reframe. In most software, memory is storage and the model is something separate that runs on top of it. Here they are closer to the same thing. Every closed deal is a labeled example: a sequence of events, and a known outcome. The model for reading a new deal is largely what happened to the deals that looked like this one. So the memory is not a filing cabinet you occasionally search. It is the population the engine reasons over every time it scores a change or decides whether to act.
def read(new_deal, memory): # the population is the model: every closed deal is a labeled example neighbours = memory.similar(new_deal, k=K) # deals that looked like this one raw = weighted_outcome(neighbours) # what actually happened to them return calibrate(raw, memory.outcomes) # map to a true probability # as |memory| grows: neighbours get closer, calibration tightens, the read sharpensTwo things in that function get better as the memory grows, and they are worth separating. First, the neighbours get closer. With a few hundred deals, deals that looked like this one is a loose match. With tens of thousands, there is almost always a tight cluster that genuinely resembles the one in front of you, which makes the read about it sharper and more specific. A precursor that was too rare to weigh at small scale becomes measurable once enough deals carry it.
Second, the calibration tightens. Recall that a raw score has to be mapped to a true probability by checking it against outcomes. That check is only as good as the number of outcomes you have to check against. More closed deals means the mapping from score to probability is estimated from more evidence, so the probabilities the engine reports are closer to the truth. The read does not just get more confident as memory grows. It gets more correct.
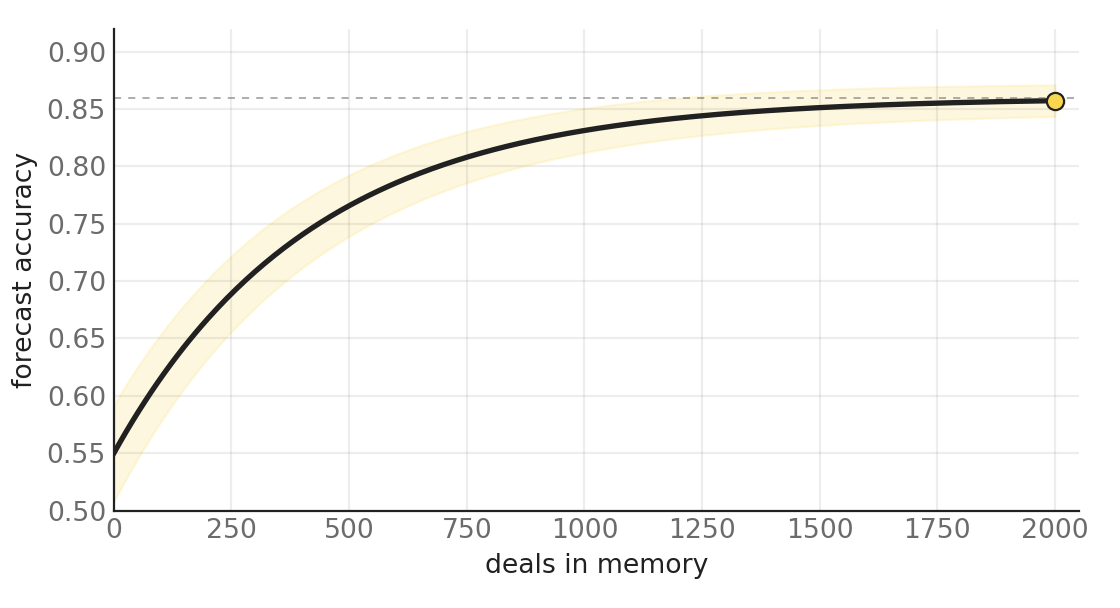
That is the curve: forecast accuracy against the number of deals in memory. It rises fast at first, as the engine gets enough examples to learn the common precursors, then bends toward a ceiling as the remaining gains come from rarer and rarer patterns. The band around it is the calibration tightening. The property that matters is the shape, not the exact numbers. Accuracy compounds with the population, and it compounds on a curve you can only climb by closing deals and keeping them connected.
This is why the memory layer is the precondition for the rest, and why the positioning matters. Yuzu is not a notetaker and not a CRM. It plugs into both: the notetaker captures the call, the CRM holds the record. What it adds is the layer that turns that pile into a population the engine can learn from, so that every deal you close makes the read on the next one a little sharper. Knowledge that compounds is not a slogan here. It is the literal shape of the accuracy curve.
